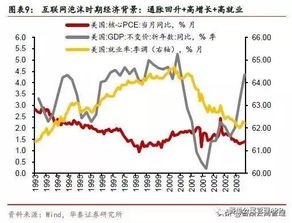
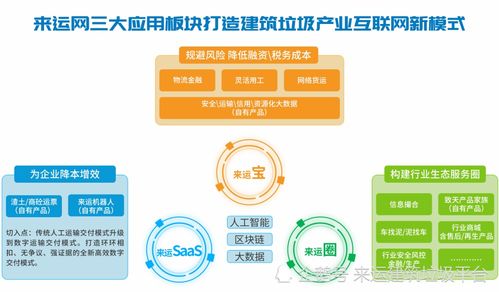
大數據時代受眾營銷變革 CAP產品與上海數據交易中心如何重塑移動廣告產業

隨著大數據時代的來臨,受眾營銷正在經歷一場深刻的變革。傳統的營銷方式正逐漸被基于數據分析的精準營銷所替代。這一變革的核心在于如何有效利用海量數據,實現對目標受眾的精準識別與觸達。
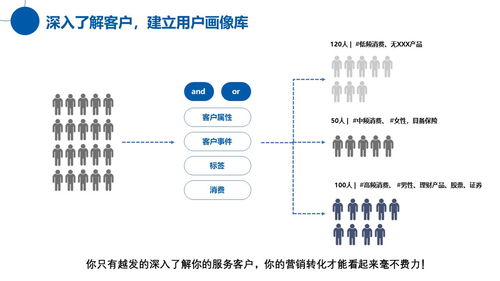
在這一背景下,CAP產品(Customer Audience Platform)應運而生,成為大數據營銷的重要工具。CAP平臺通過整合多源數據,構建全方位的用戶畫像,使廣告主能夠基于用戶的消費行為、興趣偏好和社交關系等多維度特征,實現精準的廣告投放。這種以數據驅動的營銷模式不僅提升了廣告的轉化率,還顯著降低了營銷成本,為品牌創造了更大的商業價值。
上海數據交易中心作為國內領先的數據流通平臺,在這一變革中發揮了關鍵作用。該中心通過提供安全、合規的數據交易服務,推動了互聯網數據服務產業的健康發展。在移動廣告營銷領域,上海數據交易中心為廣告主和媒體平臺搭建了高效的數據對接橋梁,使得高質量的受眾數據得以流通和利用。這不僅加速了移動廣告產業的智能化升級,還助力廣告主實現了從“廣撒網”到“精準投放”的戰略轉型。
互聯網數據服務的崛起進一步強化了大數據在營銷中的應用。借助云計算、人工智能和機器學習技術,互聯網數據服務能夠實時分析用戶行為數據,預測其潛在需求,并為營銷決策提供有力支持。例如,通過對移動應用使用數據的分析,廣告主可以識別高價值用戶群體,制定更具針對性的營銷策略。
大數據時代下的受眾營銷正朝著更加智能化和個性化的方向發展。CAP產品的應用、上海數據交易中心的支持以及互聯網數據服務的進步,共同推動了移動廣告營銷產業的創新與升級。隨著數據技術的不斷演進,受眾營銷將更加精準高效,為品牌和消費者創造雙贏的局面。
如若轉載,請注明出處:http://www.xiachenmin.cn/product/49.html
更新時間:2026-06-19 19:40:00