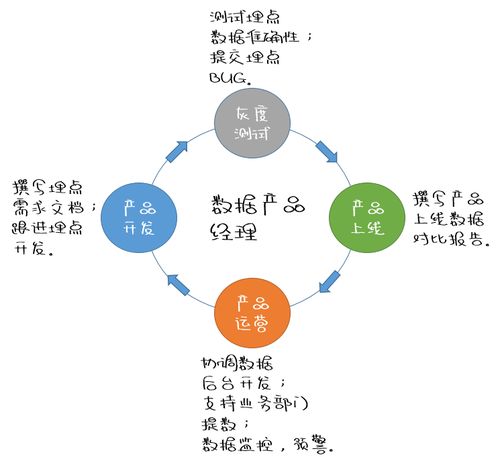
惟客數(shù)據(jù) 三年四輪融資之路,數(shù)據(jù)服務(wù)賽道的新星崛起
國內(nèi)知名互聯(lián)網(wǎng)數(shù)據(jù)服務(wù)商WakeData惟客數(shù)據(jù)(以下簡稱“惟客數(shù)據(jù)”)宣布完成2500萬美元的B輪融資,由知名投資機(jī)構(gòu)領(lǐng)投,老股東持續(xù)加碼。這距離其上一輪融資僅過去數(shù)月,也是自公司成立以來不到三年時(shí)間內(nèi)的第四輪融資。這一系列密集且高效的資本動(dòng)作,不僅為這家年輕的數(shù)據(jù)服務(wù)公司注入了強(qiáng)勁的發(fā)展動(dòng)力,更向市場(chǎng)傳遞了一個(gè)明確信號(hào):以數(shù)據(jù)驅(qū)動(dòng)業(yè)務(wù)增長的企業(yè)服務(wù)賽道,正迎來前所未有的發(fā)展機(jī)遇,而惟客數(shù)據(jù)已成為其中一顆備受矚目的新星。
從“連接”到“賦能”:惟客數(shù)據(jù)的核心定位與市場(chǎng)洞察
惟客數(shù)據(jù)成立于2018年,其創(chuàng)始團(tuán)隊(duì)深耕企業(yè)服務(wù)與數(shù)據(jù)技術(shù)領(lǐng)域多年,敏銳地捕捉到了數(shù)字經(jīng)濟(jì)時(shí)代企業(yè)面臨的普遍痛點(diǎn):盡管許多企業(yè),尤其是線下零售、地產(chǎn)、汽車、金融等傳統(tǒng)行業(yè),已經(jīng)積累了海量的數(shù)據(jù)資產(chǎn),但這些數(shù)據(jù)往往沉睡在不同系統(tǒng)、不同渠道的“孤島”中,無法有效轉(zhuǎn)化為驅(qū)動(dòng)業(yè)務(wù)決策和用戶運(yùn)營的動(dòng)能。
基于此,惟客數(shù)據(jù)提出了“連接數(shù)據(jù),賦能業(yè)務(wù)”的核心使命。其產(chǎn)品與服務(wù)并非簡單的數(shù)據(jù)采集或報(bào)表工具,而是旨在構(gòu)建一套以客戶數(shù)據(jù)平臺(tái)(CDP)為核心,涵蓋數(shù)據(jù)中臺(tái)、智能營銷、用戶運(yùn)營等模塊的一體化解決方案。通過幫助企業(yè)打通線上與線下、公域與私域、前中后臺(tái)的全鏈路數(shù)據(jù),惟客數(shù)據(jù)致力于將分散的數(shù)據(jù)資產(chǎn)轉(zhuǎn)化為統(tǒng)一的、可分析的、可行動(dòng)的“客戶數(shù)據(jù)資產(chǎn)”,進(jìn)而賦能企業(yè)實(shí)現(xiàn)精準(zhǔn)營銷、精細(xì)化運(yùn)營和智能化決策,最終提升客戶體驗(yàn)與商業(yè)價(jià)值。
不到三年,四輪融資:資本為何持續(xù)看好?
惟客數(shù)據(jù)在成立不到三年的時(shí)間里,迅速完成了從天使輪到B輪的四輪融資,累計(jì)融資額已頗具規(guī)模。這背后,是資本市場(chǎng)對(duì)其商業(yè)模式、技術(shù)實(shí)力、市場(chǎng)前景及團(tuán)隊(duì)執(zhí)行力的高度認(rèn)可。
- 賽道前景廣闊:數(shù)字化轉(zhuǎn)型已成為所有企業(yè)的“必修課”。后疫情時(shí)代,企業(yè)對(duì)降本增效、挖掘存量客戶價(jià)值的需求更為迫切。以數(shù)據(jù)驅(qū)動(dòng)運(yùn)營和增長,是公認(rèn)的核心路徑。IDC等多家機(jī)構(gòu)報(bào)告顯示,中國大數(shù)據(jù)與數(shù)據(jù)智能服務(wù)市場(chǎng)正保持高速增長,為企業(yè)提供數(shù)據(jù)服務(wù)的賽道天花板極高。
- 清晰的商業(yè)化路徑與標(biāo)桿案例:惟客數(shù)據(jù)沒有停留在技術(shù)概念層面,而是深入行業(yè)場(chǎng)景,聚焦于線下屬性強(qiáng)、客戶生命周期價(jià)值高、數(shù)字化轉(zhuǎn)型需求迫切的領(lǐng)域,如地產(chǎn)、零售、汽車和金融。其已成功服務(wù)了碧桂園、融創(chuàng)、屈臣氏、百安居、招商銀行、廣汽集團(tuán)等眾多頭部企業(yè),打造了可復(fù)制的標(biāo)桿案例。這些成功實(shí)踐證明了其解決方案的有效性和商業(yè)價(jià)值,為規(guī)模化擴(kuò)張奠定了基礎(chǔ)。
- 扎實(shí)的產(chǎn)品與技術(shù)壁壘:惟客數(shù)據(jù)的核心產(chǎn)品“惟客云”平臺(tái),集數(shù)據(jù)整合、治理、分析、應(yīng)用與運(yùn)營于一體。其技術(shù)團(tuán)隊(duì)在實(shí)時(shí)數(shù)據(jù)處理、大數(shù)據(jù)平臺(tái)架構(gòu)、AI算法模型等方面具備深厚積累。面對(duì)企業(yè)復(fù)雜異構(gòu)的數(shù)據(jù)環(huán)境,惟客數(shù)據(jù)能夠提供穩(wěn)定、高效、安全的部署與交付能力,這構(gòu)成了其重要的技術(shù)護(hù)城河。
- 卓越的團(tuán)隊(duì)執(zhí)行力:創(chuàng)始團(tuán)隊(duì)兼具深厚的技術(shù)背景、豐富的企業(yè)管理軟件經(jīng)驗(yàn)以及對(duì)垂直行業(yè)的深刻理解。在競(jìng)爭(zhēng)激烈的市場(chǎng)中,團(tuán)隊(duì)展現(xiàn)出了快速的產(chǎn)品迭代能力、精準(zhǔn)的行業(yè)聚焦策略和高效的客戶落地能力,這是獲得資本持續(xù)青睞的關(guān)鍵。
B輪融資后的新征程:深化、拓展與生態(tài)構(gòu)建
此次完成的2500萬美元B輪融資,對(duì)惟客數(shù)據(jù)而言,絕非簡單的資本疊加,而是標(biāo)志著公司進(jìn)入了一個(gè)全新的發(fā)展階段。資金將主要投向以下幾個(gè)方面:
- 產(chǎn)品研發(fā)與技術(shù)升級(jí):進(jìn)一步加大在人工智能、機(jī)器學(xué)習(xí)等前沿技術(shù)上的投入,深化產(chǎn)品智能化水平,開發(fā)更多開箱即用的場(chǎng)景化應(yīng)用模塊,降低企業(yè)使用門檻。加強(qiáng)數(shù)據(jù)安全與隱私保護(hù)能力,以應(yīng)對(duì)日益嚴(yán)格的監(jiān)管要求。
- 行業(yè)縱深與市場(chǎng)拓展:在鞏固現(xiàn)有優(yōu)勢(shì)行業(yè)(如地產(chǎn)、零售)領(lǐng)導(dǎo)地位的向更多數(shù)據(jù)價(jià)值密度高、轉(zhuǎn)型意愿強(qiáng)的行業(yè)拓展,例如制造業(yè)、文旅、教育等。深化區(qū)域市場(chǎng)覆蓋,建立更完善的銷售與服務(wù)網(wǎng)絡(luò)。
- 生態(tài)合作與人才建設(shè):積極與云服務(wù)商、咨詢公司、垂直行業(yè)ISV(獨(dú)立軟件開發(fā)商)等合作伙伴構(gòu)建生態(tài)聯(lián)盟,共同為企業(yè)客戶提供更完整的數(shù)字化轉(zhuǎn)型解決方案。吸引更多頂尖的技術(shù)、產(chǎn)品與行業(yè)專家加入,為公司的長期發(fā)展儲(chǔ)備核心人才。
- 品牌建設(shè)與認(rèn)知提升:通過本輪融資的聲量,進(jìn)一步提升“惟客數(shù)據(jù)”在企服市場(chǎng)和目標(biāo)客戶中的品牌知名度與影響力,鞏固其作為頭部客戶數(shù)據(jù)平臺(tái)與服務(wù)商的地位。
行業(yè)啟示與未來展望
惟客數(shù)據(jù)的快速崛起,是中國企業(yè)服務(wù)市場(chǎng),特別是數(shù)據(jù)智能服務(wù)領(lǐng)域蓬勃發(fā)展的一個(gè)縮影。它揭示了幾個(gè)重要趨勢(shì):
“數(shù)據(jù)即資產(chǎn)”從理念走向?qū)嵺`。越來越多的企業(yè)愿意為能夠?qū)?shù)據(jù)轉(zhuǎn)化為實(shí)際業(yè)務(wù)價(jià)值的產(chǎn)品和服務(wù)付費(fèi),這為數(shù)據(jù)服務(wù)商創(chuàng)造了真實(shí)的、可持續(xù)的市場(chǎng)需求。
“業(yè)務(wù)價(jià)值”取代“技術(shù)炫技”成為核心評(píng)判標(biāo)準(zhǔn)。成功的服務(wù)商必須深入業(yè)務(wù)場(chǎng)景,理解行業(yè)Know-how,提供能解決具體問題的方案,而非空談技術(shù)架構(gòu)。
資本正向具備“硬實(shí)力”的企服公司集中。市場(chǎng)已度過早期的概念炒作期,資本更加理性,青睞那些有扎實(shí)技術(shù)、清晰商業(yè)模式、經(jīng)過市場(chǎng)驗(yàn)證并能實(shí)現(xiàn)規(guī)模化增長的團(tuán)隊(duì)。
隨著數(shù)字化轉(zhuǎn)型的浪潮奔涌不息,數(shù)據(jù)作為核心生產(chǎn)要素的地位將愈發(fā)凸顯。對(duì)于惟客數(shù)據(jù)而言,三年四輪融資是輝煌的起點(diǎn),但更大的挑戰(zhàn)在于如何利用資本和先發(fā)優(yōu)勢(shì),持續(xù)構(gòu)建核心競(jìng)爭(zhēng)力,在愈發(fā)激烈的市場(chǎng)競(jìng)爭(zhēng)中保持領(lǐng)先,真正成長為賦能千行百業(yè)數(shù)字化轉(zhuǎn)型的中堅(jiān)力量。其發(fā)展路徑,也將為整個(gè)數(shù)據(jù)服務(wù)行業(yè)提供寶貴的借鑒與思考。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.xiachenmin.cn/product/61.html
更新時(shí)間:2026-06-19 23:53:31