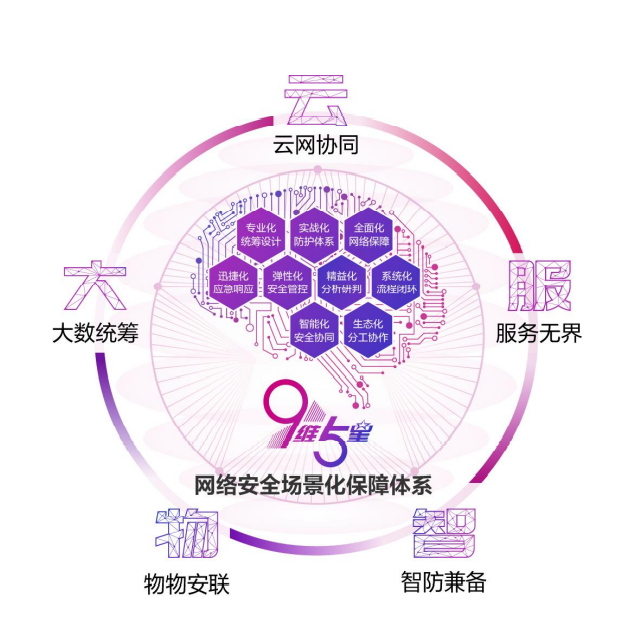
圖說智能紡織工廠丨河北南冠科技建設(shè)國(guó)際一流數(shù)字化車間 互聯(lián)網(wǎng)數(shù)據(jù)服務(wù)

在飛速發(fā)展的工業(yè)4.0時(shí)代,傳統(tǒng)紡織行業(yè)正迎來數(shù)字化轉(zhuǎn)型的浪潮。河北南冠科技有限公司緊抓機(jī)遇,傾力打造國(guó)際一流的智能紡織工廠,以數(shù)字化車間和互聯(lián)網(wǎng)數(shù)據(jù)服務(wù)為核心,推動(dòng)紡織制造邁向高效、智能與環(huán)保的新高度。
河北南冠科技的智能紡織工廠,不再是傳統(tǒng)意義上的生產(chǎn)車間,而是一個(gè)高度集成的數(shù)字化生態(tài)系統(tǒng)。通過引入先進(jìn)的物聯(lián)網(wǎng)技術(shù)、大數(shù)據(jù)分析和人工智能算法,工廠實(shí)現(xiàn)了從原料采購(gòu)、生產(chǎn)調(diào)度到成品出庫(kù)的全流程智能化管理。在數(shù)字化車間內(nèi),每一臺(tái)設(shè)備都配備了傳感器,實(shí)時(shí)采集運(yùn)行數(shù)據(jù),并通過互聯(lián)網(wǎng)平臺(tái)進(jìn)行集中監(jiān)控與優(yōu)化。這不僅顯著提升了生產(chǎn)效率,降低了人工成本,還確保了產(chǎn)品質(zhì)量的穩(wěn)定性與可追溯性。
互聯(lián)網(wǎng)數(shù)據(jù)服務(wù)是南冠科技智能工廠的另一大亮點(diǎn)。工廠利用云計(jì)算平臺(tái),將海量生產(chǎn)數(shù)據(jù)存儲(chǔ)、分析與應(yīng)用,形成精準(zhǔn)的決策支持系統(tǒng)。例如,通過對(duì)歷史訂單和市場(chǎng)需求數(shù)據(jù)的分析,系統(tǒng)能夠自動(dòng)預(yù)測(cè)生產(chǎn)計(jì)劃,優(yōu)化資源配置,減少庫(kù)存積壓。同時(shí),數(shù)據(jù)服務(wù)還擴(kuò)展到供應(yīng)鏈管理,幫助企業(yè)與上下游合作伙伴實(shí)現(xiàn)信息共享與協(xié)同,打造敏捷、透明的供應(yīng)鏈網(wǎng)絡(luò)。這種數(shù)據(jù)驅(qū)動(dòng)的運(yùn)營(yíng)模式,讓南冠科技在競(jìng)爭(zhēng)激烈的紡織市場(chǎng)中脫穎而出。
南冠科技注重可持續(xù)發(fā)展,數(shù)字化車間在節(jié)能環(huán)保方面表現(xiàn)卓越。通過智能能源管理系統(tǒng),工廠實(shí)時(shí)監(jiān)控能耗數(shù)據(jù),自動(dòng)調(diào)整設(shè)備運(yùn)行狀態(tài),有效降低碳排放。結(jié)合循環(huán)經(jīng)濟(jì)理念,南冠科技還利用數(shù)據(jù)分析優(yōu)化原材料使用,減少浪費(fèi),實(shí)現(xiàn)了經(jīng)濟(jì)效益與環(huán)境效益的雙贏。
河北南冠科技將繼續(xù)深化數(shù)字化轉(zhuǎn)型,探索5G、邊緣計(jì)算等前沿技術(shù)的應(yīng)用,進(jìn)一步提升智能紡織工廠的自動(dòng)化與智能化水平。在互聯(lián)網(wǎng)數(shù)據(jù)服務(wù)的賦能下,南冠科技不僅為國(guó)內(nèi)紡織行業(yè)樹立了標(biāo)桿,也將助力中國(guó)制造在全球舞臺(tái)上贏得更多認(rèn)可。智能紡織,已不再是遙遠(yuǎn)的愿景,而是南冠科技正在踐行的現(xiàn)實(shí)。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.xiachenmin.cn/product/35.html
更新時(shí)間:2026-06-19 08:07:22