隨著大數據與人工智能技術的深度融合,智慧農業已成為現代農業發展的重要方向。針對農產品市場波動性大、供需信息不對稱等痛點,設計并實現一個集數據處理、預測分析與智能推薦于一體的綜合性系統,具有重要的實踐價值。本畢業設計旨在融合Spark、Hadoop、Hive、LLM大模型及Django框架,構建一個先進的智慧農業決策支持系統,核心功能涵蓋農產品價格預測、銷量預測與個性化推薦。
1. 系統總體架構與核心技術棧
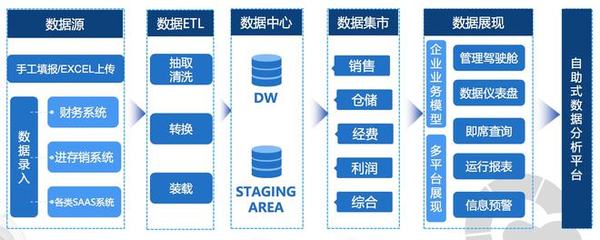
系統采用分層架構設計,以保障高可擴展性與處理能力。
- 數據存儲與計算層: 以Hadoop HDFS作為海量農業數據(如歷史價格、天氣、種植面積、市場交易、電商評論)的分布式存儲基礎。利用Hive構建數據倉庫,進行結構化的數據管理與離線查詢,為上層分析提供清潔、整合的數據集。
- 大數據處理與分析層: Apache Spark作為核心計算引擎,憑借其內存計算優勢和豐富的庫(Spark SQL, MLlib, Streaming),高效完成數據的ETL(抽取、轉換、加載)、特征工程,并并行化地訓練傳統的機器學習預測模型(如回歸、時間序列分析)。
- 智能模型層: 引入大型語言模型作為系統的智能增強。一方面,LLM可用于處理非結構化文本數據(如政策新聞、社交媒體輿情、農產品描述),通過微調或提示工程,提取影響價格和銷量的語義特征與情感傾向。另一方面,結合傳統特征與LLM提取的深層語義特征,構建更精準的融合預測模型。在推薦模塊,LLM可深入理解用戶查詢和農產品特性,生成更人性化、解釋性更強的推薦理由。
- 應用與服務層: 采用Django這一高性能Python Web框架搭建后端RESTful API服務,并管理前端展示界面。Django負責接收用戶請求(如查詢特定農產品預測)、調用Spark/LLM模型服務,并將預測結果、推薦列表可視化呈現給農戶、經銷商或消費者。
2. 核心功能模塊詳解
2.1 農產品價格與銷量預測系統
這是系統的智能核心。數據處理流程始于Hive中的歷史數據整合,經由Spark進行大規模特征計算(如移動平均、周期波動、關聯因素量化)。預測模型采用混合策略:
- 基礎預測模型: 使用Spark MLlib構建如梯度提升樹、隨機森林或ARIMA等模型,處理數值型和類別型特征。
- LLM增強分析: 將相關的網絡文本信息輸入LLM,提取“政策扶持力度”、“市場恐慌情緒”、“消費趨勢關鍵詞”等軟性指標,作為特征補充。
- 融合與預測: 將傳統特征與LLM提取的特征合并,訓練最終的集成預測模型,輸出未來短期(如一周)和中長期(如一季)的價格區間與銷量預估,并通過Django前端以圖表形式直觀展示。
2.2 農產品智能推薦系統
推薦系統服務于兩端:為消費者推薦可能感興趣的農產品,為生產者推薦有市場潛力的種植品類。
- 協同過濾與內容推薦: 利用Spark MLlib的交替最小二乘法實現基于用戶-購買行為的協同過濾。基于農產品的品類、產地、特性等屬性進行內容推薦。
- LLM驅動的語義與情境推薦: LLM在此發揮關鍵作用。它能深度解析農產品的自然語言描述(如“多汁”、“有機種植”),并與用戶畫像(可能由歷史行為或查詢文本推斷)進行語義匹配。例如,當用戶搜索“適合夏天清淡飲食的蔬菜”,LLM可理解其深層需求,并結合時令、氣候數據,推薦黃瓜、苦瓜等,并生成自然的推薦解釋。
2.3 數據處理與可視化平臺
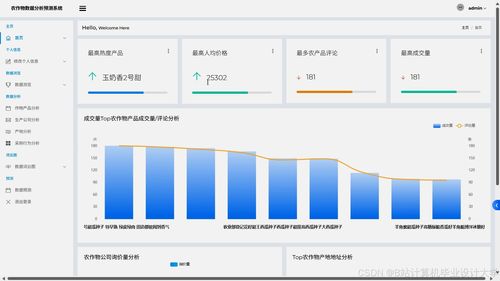
系統通過Django提供統一的數據管理與可視化門戶。用戶不僅可以查看預測和推薦結果,還能上傳本地數據,觸發后臺的Spark數據處理流水線。系統提供數據看板,動態展示不同區域、不同品類農產品的市場價格走勢、預測對比及熱銷榜單。
3. 技術挑戰與創新點
- 挑戰: 多源異構數據(數值、文本)的融合處理;LLM大模型與大數據框架的高效集成與部署;預測模型在農業領域的可解釋性要求。
- 創新點: 將LLM的深層語義理解能力與傳統大數據分析技術(Spark/Hadoop)有機結合,突破了傳統預測模型僅依賴結構化數據的局限,實現了“數據+語義”的雙輪驅動決策。系統不僅是一個預測工具,更是一個融合了市場情報分析的智慧農業大腦。
4.
本設計提出的系統,通過整合從底層分布式存儲到上層智能應用的完整技術棧,構建了一個功能全面、技術先進的智慧農業決策支持平臺。它不僅能幫助農業生產者與經營者規避市場風險、優化種植與銷售策略,也能為消費者提供更個性化的購物體驗,是推動農業數字化轉型、實現精準農業與智慧供應鏈的一次有益探索。該系統架構清晰,模塊耦合度低,便于未來進一步集成物聯網傳感器數據、圖像識別等更多技術,拓展其應用邊界。